3 minutes
Implementing a general-use arena

Now that we have learned about arenas and allocators, we can get our hands dirty with an implementation of an arena.
Best Fit Arena
You see, for the last couple of months, I’ve been updating RiftCore with new features. RiftCore is a cross-platform framework I use for C++ projects, and it lacked some memory management.
So the time came to design a general-purpose arena!
This article will describe the design and implementation of a Best Fit Arena. Feel free to come up with a better name though (and put it in the comments below!)
General-purpose?
A general-purpose allocator (or arena) must be able to work on all scenarios with out any big limitation. As such, it has to be able to:
- Allocate in any order and any size
- Deallocate in any order
- Use (and reuse) all space available
- Minimize fragmentation
In RiftCore, Arenas always carry the size of the pointer in their Free() function.
This opens the door to some optimizations, but, don’t worry, the BestFitArena can be adapted to avoid this pattern.
Implementation
A BestFitArena works by tracking all unused spaces, called free slots.
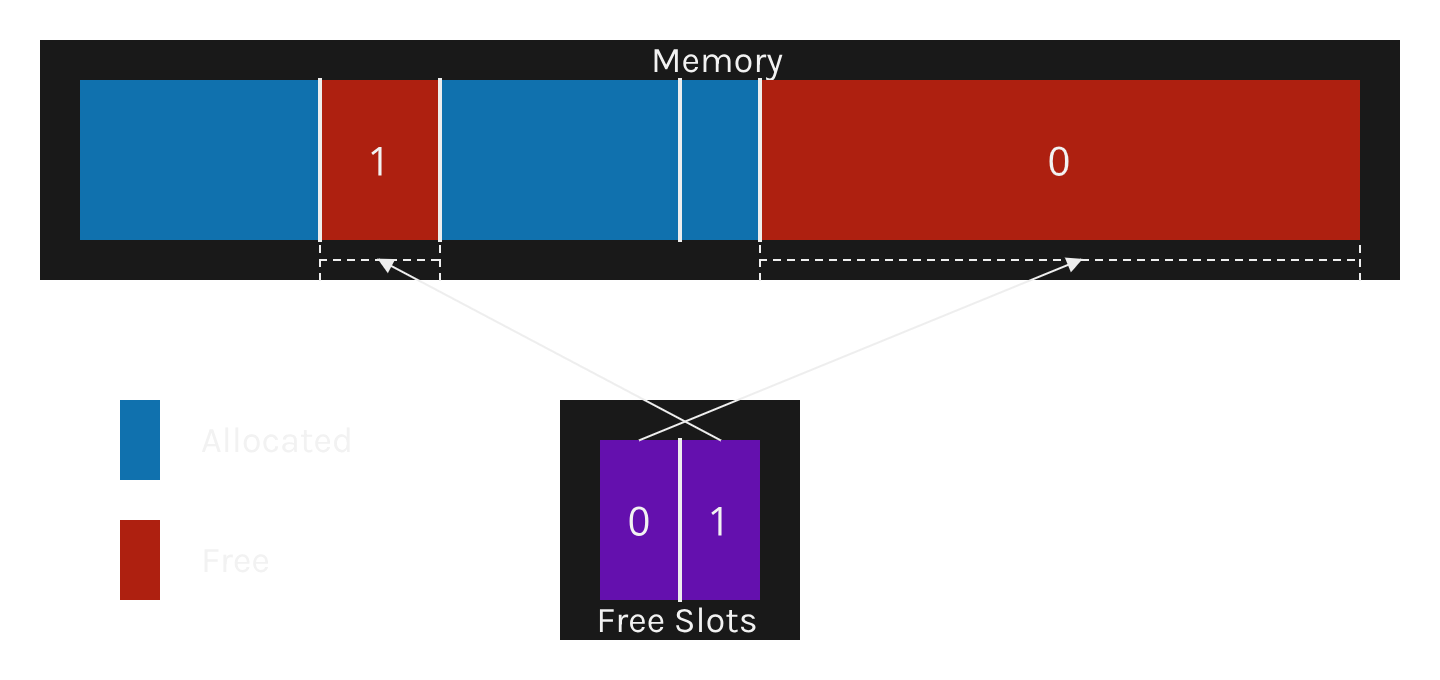
Let’s go through what we see in this picture:
- Like most allocators, we have one or multiple memory blocks of pre-allocated memory.
- We also keep a list of
FreeSlots, sorted by size. Bigger first. - We don’t track allocations in any way. No headers, no offsets and no sizes.
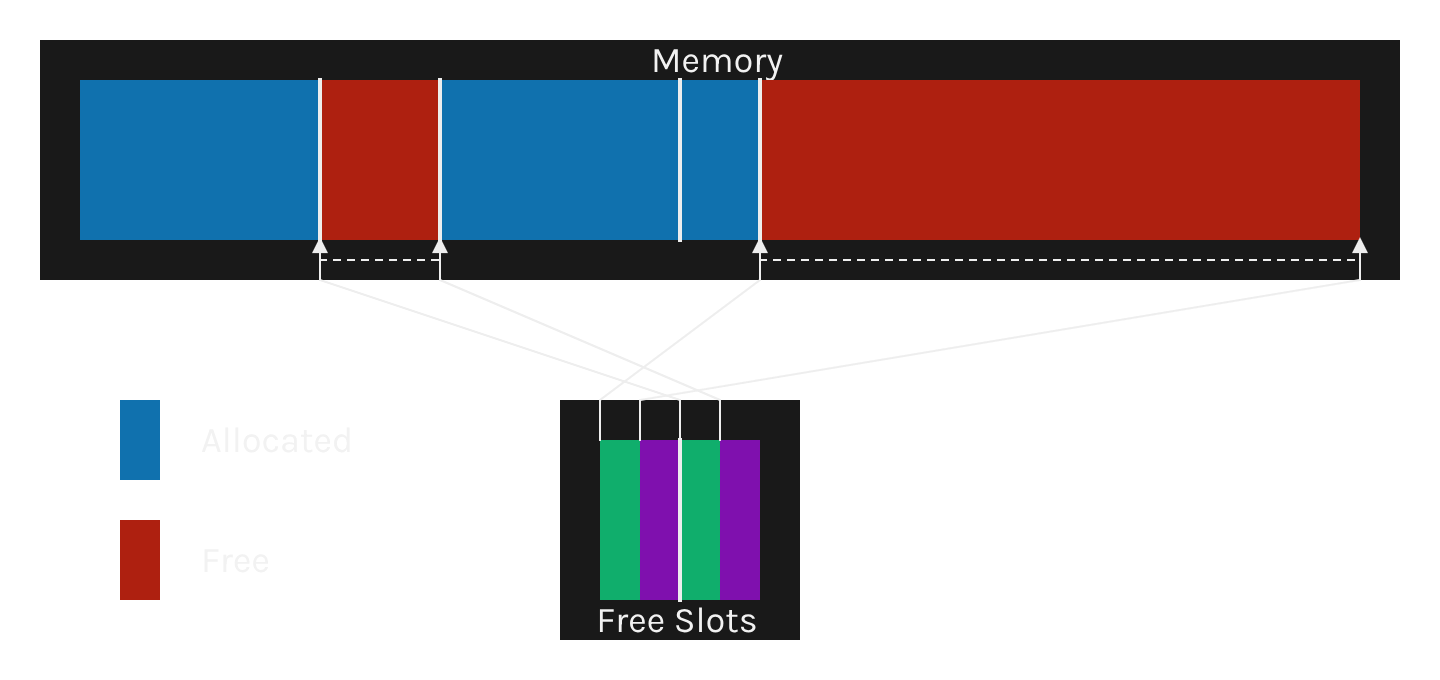 Seen in more detail, each slot points to the start of its memory and its size.
Seen in more detail, each slot points to the start of its memory and its size.
This algorithm has zero overhead when fragmentation is low. The less fragmentation, the more performant it is. However, it is also designed to minimize it, and, as you will see later, even in an scenario with a lot of fragmentation, performance is still excellent.
Allocation
Allocation will always pick the smallest free slot possible and extract the pointer from it.
Then, this slot is reduced removing the used space from it.
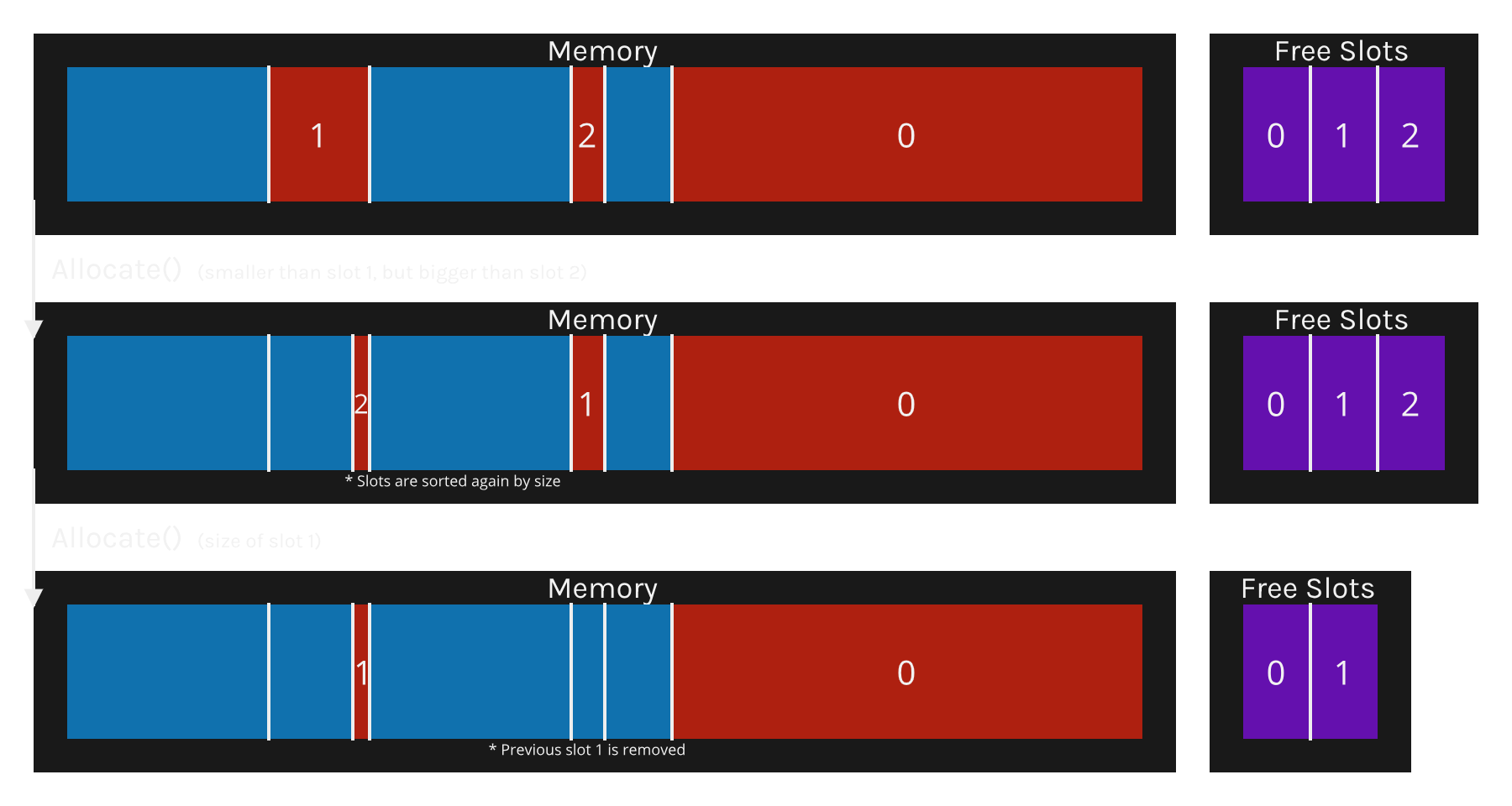
Find Smallest Slot
Before anything else, we check if the arena is marked as pending sort. This is an optimization that prevents unnecessary sorts on consequent Free calls. But we also perform shrink on the slots if necessary.
Once we know all slots are sorted, we perform a binary search by size. The binary search will provide a complexity of O(logN).
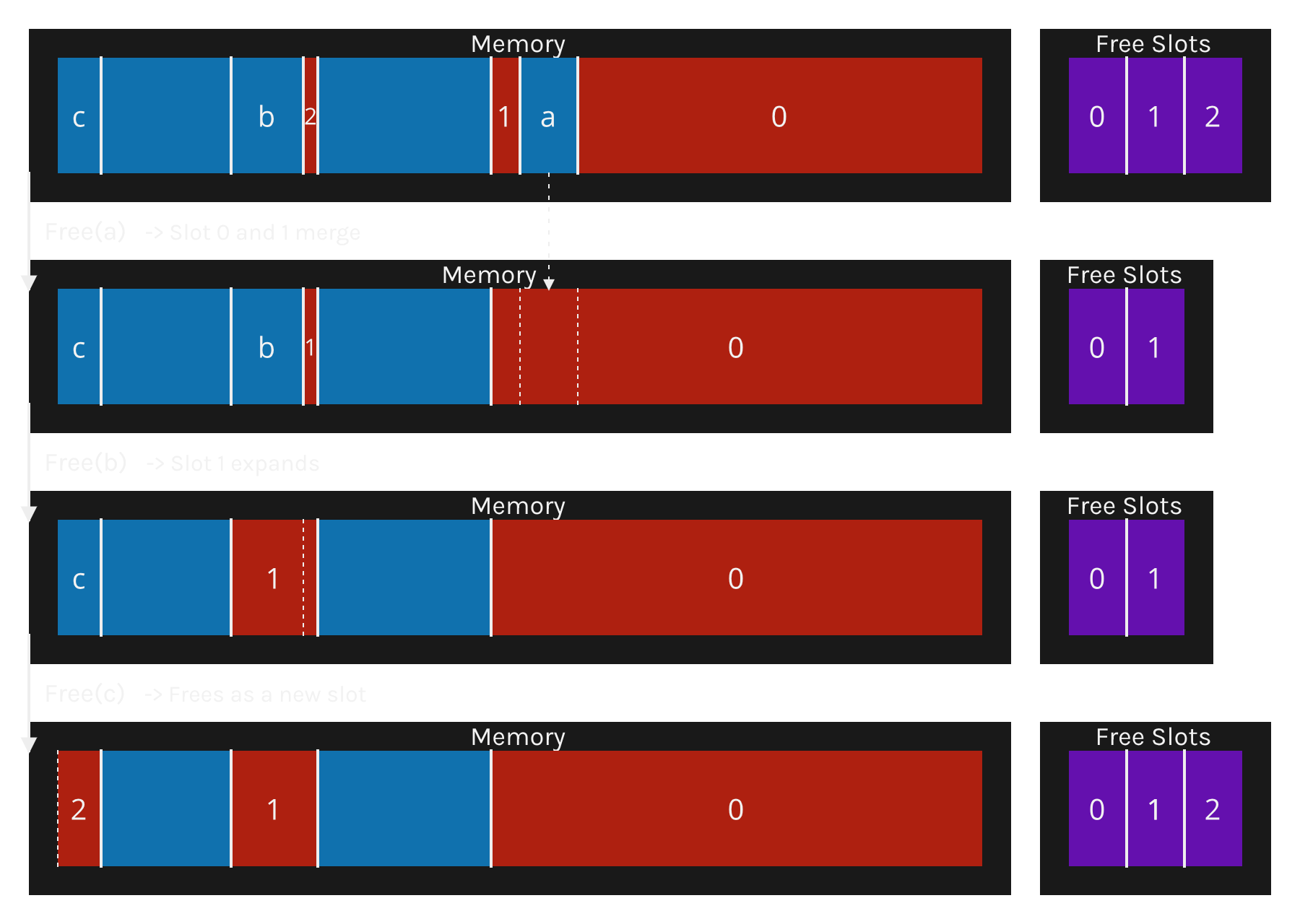
Free
Free expands the free slots that “touch” the freed memory, absorb it and growing the slot.
We know of the size of the allocation because it is contained on the free slots list which we check anyway.
PS: This is a post I never published when I wrote it. So some details might be missing but feel free to ask any questions :)
445 Words
2022-02-03